Accuracy tells you whether an AI agent got the right answer. It says almost nothing about how it got there, how much it cost, or whether it would have needed a human to bail it out halfway through. As AI agents move from research demos into production systems handling real workflows — customer support, financial analysis, healthcare triage — the gap between "technically correct" and "actually useful" becomes a serious engineering and business problem.
Beyond Accuracy: 5 Metrics That Actually Matter for AI Agents Image by Editor
Why Standard LLM Metrics Fall Short for Agentic Systems
Static large language model evaluations were built around a simple question: did the model produce the correct output? That framing works reasonably well for benchmarks and classification tasks. But AI agents operate differently — they take sequences of actions, call external tools and APIs, make decisions across multiple steps, and interact with environments that push back. A single accuracy score collapses all of that complexity into one number, hiding exactly the things that matter most when you're deciding whether to deploy an agent at scale or trust it with a high-stakes task.
The five metrics below address what accuracy misses: procedural quality, tool use, autonomy, resilience, and cost efficiency. Each one captures a distinct dimension of agent behavior, and together they give a much more honest picture of how a system actually performs.
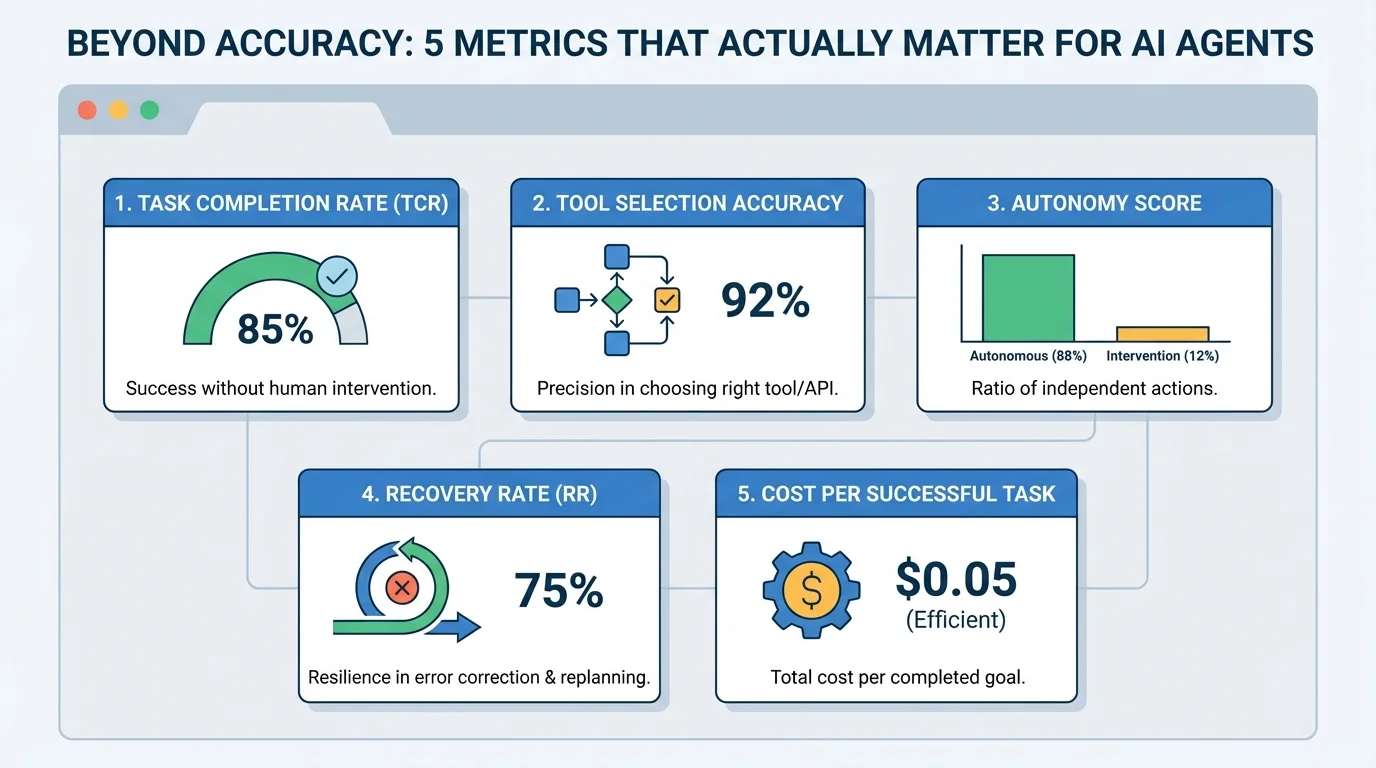
The Five Metrics Worth Tracking
Task Completion Rate (TCR), sometimes called Success Rate, measures the percentage of assigned tasks an agent finishes without human intervention. It's the most intuitive of the five — a customer support agent that resolves a refund request end-to-end scores a completion; one that stalls and escalates doesn't. The catch is treating it as a pure binary. An agent that technically completes a task but takes three times longer than expected, or burns through excessive compute to get there, can look identical to an efficient one under TCR alone. More on this in this paper.
Tool Selection Accuracy measures how consistently an agent picks the right function, API, or external component at each decision point. In domains like finance, where calling the wrong tool can have real downstream consequences, this matters enormously. Evaluating it properly requires a defined ground-truth path — which is straightforward in structured workflows but harder to establish in open-ended tasks. See this overview for a deeper look.
The Autonomy Score — also framed as Human Intervention Rate — tracks the ratio of actions the agent takes independently versus those requiring human clarification, correction, or approval. It's directly tied to ROI: the more an agent needs hand-holding, the less value it delivers. That said, high autonomy isn't universally desirable. In healthcare or legal contexts, a low autonomy score might reflect appropriate caution rather than poor performance. Anthropic has published research on measuring this that's worth reading before applying it to safety-critical deployments.
Recovery Rate captures how often an agent detects an error and successfully replans to correct it. Agents that interact heavily with external systems will inevitably hit unexpected states — a failed API call, an ambiguous response, a tool returning null. Recovery Rate measures resilience to those moments. One nuance: a very high recovery rate can actually be a warning sign, suggesting the agent is unstable and constantly correcting itself rather than operating cleanly. This paper explores the metric in more detail.
Cost per Successful Task — also called token efficiency or cost-per-goal — measures the total computational or economic cost required to complete one task successfully. This is the metric that tends to get ignored during development and then becomes urgent the moment someone tries to scale. An agent that costs $0.40 per task in testing might be perfectly acceptable; the same agent handling 100,000 tasks a day is a different conversation entirely. This guide covers practical approaches to tracking it.
What These Metrics Mean for Building and Deploying Agents
No single metric here is sufficient on its own — that's the point. TCR without Cost per Successful Task can hide inefficiency. Autonomy Score without Recovery Rate can mask fragility. Tool Selection Accuracy without TCR tells you the agent makes good individual decisions but says nothing about whether it finishes the job. The real value comes from using them together as a dashboard rather than optimizing for any one number in isolation.
There's also a context dependency that runs through all five. What counts as an acceptable Autonomy Score in a customer service bot is very different from what's acceptable in a clinical decision support system. Recovery Rate thresholds that signal instability in one domain might reflect healthy error-handling in another. These metrics require interpretation, not just measurement — which means the teams building and evaluating agents need to define acceptable ranges before deployment, not after something goes wrong.
The shift toward agentic AI is pushing evaluation frameworks to catch up with what these systems are actually doing. Accuracy was a reasonable starting point; it's no longer enough on its own.
Measuring whether an AI agent is actually working turns out to be a much harder problem than most teams expect. Accuracy — the go-to metric for traditional machine learning models — tells you almost nothing useful when the system you're evaluating doesn't just classify inputs but takes actions, uses tools, and operates across multi-step workflows. The gap between "the model got the right answer" and "the agent did the right thing" is where most evaluation frameworks fall apart.
Why Accuracy Fails as a Standalone Metric for Agents
Traditional ML evaluation was built around a simple contract: given an input, predict an output, compare to ground truth. Agents break that contract entirely. They operate over sequences of decisions, call external tools, manage state across turns, and often produce outputs that can't be reduced to a single correct answer. An agent that reaches the right final result through a broken reasoning chain, or one that succeeds on a task but takes three times as many steps as necessary, won't look broken under a pure accuracy lens — but it is.
This is the core problem the article addresses. When agents are deployed in real workflows, the metrics that matter are the ones that capture behavior across the full execution path, not just the endpoint. Teams that skip this and rely on accuracy alone tend to discover the gaps in production, which is the worst possible place to find them.
The 5 Metrics That Give a More Complete Picture
The article identifies five evaluation dimensions that collectively cover what accuracy misses. Task completion rate measures whether the agent actually finishes what it was asked to do — straightforward, but often surprisingly low in early deployments. Tool call precision tracks whether the agent is invoking the right tools at the right times, which matters enormously in agentic systems where a bad tool call can cascade into downstream failures.
Step efficiency looks at how many actions the agent takes to complete a task relative to an optimal path. An agent that completes tasks but does so through unnecessarily long chains is expensive to run and harder to debug. Faithfulness to instructions evaluates whether the agent's behavior actually reflects what it was told to do — a metric that becomes critical when agents are given complex, multi-part prompts or operate under specific constraints. Finally, recovery rate measures how well an agent handles errors and unexpected states, which is arguably the most operationally relevant metric for anything running in a live environment.
What This Means for Teams Building and Deploying Agents
The shift from model evaluation to agent evaluation isn't just a technical adjustment — it reflects a broader maturation in how the industry thinks about AI systems in production. Models are artifacts. Agents are processes. Evaluating a process requires tracking it over time, across states, and under conditions that don't always match the training distribution.
For teams building agents today, the practical implication is that evaluation infrastructure needs to be designed alongside the agent itself, not bolted on afterward. Logging tool calls, tracking step counts, and building test harnesses that simulate failure conditions are engineering investments that pay off quickly once you're trying to diagnose why an agent is underperforming in a specific scenario. The five metrics outlined here aren't exhaustive, but they cover the most common failure modes that pure accuracy evaluation leaves invisible.
The broader point is that as agents take on more consequential tasks — managing workflows, interacting with external systems, making decisions with real downstream effects — the cost of inadequate evaluation goes up proportionally. Getting the measurement framework right early is one of the more leveraged things a team can do.

")

")


